

Let’s get technical 🔧
Let’s get technical 🔧
This week, we look at the core technical SEO concepts publishers need to know!

Hello and welcome back! It’s Shelby here, enjoying whatever “summer” is left before the best season of all arrives for a short-lived time.
Firstly, Jessie and I want to say a big hello to all of our new friends that found us over the past week! Shoutout to Journalism.co.uk for including WTF is SEO? on their list of 19 essential newsletters for journalists (us in the company of Nieman Lab?! Yes please).
Next weekend is also the Labour Day long weekend in Canada, which means the last relaxing weekend before the Canadian federal election. Both halves of WTF is SEO? will be taking a nice break, returning to your inboxes on September 13 (which also happens to be my first day with Mashable as their new SEO Manager!).
We’re also looking for more folks to participate in our #AskaNewsSEO series. Want to be a part? Email us.
As for today’s issue, we’re diving into a 101-level guide all around technical SEO. This will be the beginning of a series of issues that help explain the technical components that make search engines crawl your site and rank it for particular keywords that you work so hard to target.

Let’s get technical.
In this issue:
What is technical SEO?
5 key terms to know
How to incorporate technical components into your strategy

THE 101
What is technical SEO?
Technical SEO focuses on optimizing the actual infrastructure of your site for search engines. This form of optimization helps spiders crawl your site better and therefore can help your rankings.
Search engines crawl content across the internet, processing the information that it finds into an index that is then used to provide content for relevant queries. For news, this process can look like:
A story is published > search engine spider crawls the code/content > spider stores in appropriate file > reader searches something > the story surfaces if it matches the appropriate query.
There are a lot of components to technical SEO. As an audience editor, you may not need to get as in-depth as some SEO specialists will. However, as Lindsey Wiebe, International SEO Manager at The New York Times said, editorial and technical SEO need to function in tandem for news organizations to succeed.
While you don’t need to be able to read or write code, it is good to have a solid understanding of how a website appears in a browser, what the website is made of and the languages that are used to construct it.
The three most common are:
Hypertext markup language (HTML): What the website says. This is the contents of the site. If the website is a house, HTML is the structure (walls, floors, ceiling).
Cascading styling sheets (CSS): How the website looks. These are the style directives for your site to take on certain fonts, colours or layouts/designs. In our house analogy, CSS is the interior decoration (paint, furniture, plants).
Javascript (JS): How the website interacts. This can be moving images or GIFs, dynamic actions that the site can take that make the website non-static. In our house analogy, JavaScript is our electricity, water and candles.
These languages are ones that will commonly interact with SEO-critical page elements, such as the text, links, tags.
But, just like content, we can optimize our sites to better serve your readers by making them more accessible.
Today, we’ll do an overview of the following topics and when, as an editor, you’ll need to interact with them and make changes.
What is “indexable” and “non-indexable”;
What are broken links and how to crawl a site;
What is a sitemap and when do I need one?;
What are the HTTP status codes and what do they mean?;
What is duplicate or thin content?
Read more: The definitive guide to technical SEO by Backlinko
Indexable and non-indexable
What it is: You may read folks talking about indexable versus non-indexable content. This refers to the pages on your site that can or cannot be read by crawlers.
This may seem counterintuitive, given that most of our strategies are around having content indexed by Google to be found by readers. But your whole site is not catered to a search audience, and some pages may be harder to render than others.
In fact, you may have pages on the site that can’t be indexed because of a contractual agreement (e.g.: publisher agreements with certain wire services), may be a private page you don’t want found or even as simple as your login page for paying subscribers.
But there are other factors that can affect how a page is read and therefore, if it is indexable.
Is this page an “orphan” page, aka does not have any links to other internal pages?
Is this page missing static URLs (URLs that do not change)?
Is there too much JavaScript running the page?
Does this page not use HTML (Word, Excel, PDF documents, etc.)?
What to do: Type site: followed immediately by the name of your site into a Google search bar. This will give you every page from your site that is currently indexed by Google. From here, take a look at what is indexed - do they all make sense to be indexed? Should a login page have a noindex directive instead?
Broken links
What is it: Exactly what it sounds like: a series of links that direct to broken or no-longer-existing content. If you link to a site and the link returns a 404 error or does not render the page, the URL is considered broken. These links can be to pages on your own site or external sites
These are especially bad for SEO. We want good, high-quality links to pages that will help the user. If we are serving readers a broken link, crawlers assume it is spam or not useful.
What to do: Crawl your site! Broken link checkers come in droves, so pick one that works best for you (personal favourite: Screaming Frog). Collect a list of broken links and work on fixing them. Fixing can be:
Changing the broken link for a non-broken link;
Redirecting the broken link to its appropriate link;
Taking the link out entirely (only if you cannot do one of the above).
Sitemaps
What is it: A sitemap is a blueprint of your website. It helps search engines find, crawl and index your website’s content in an easy way, versus crawling each page one-by-one.
Sitemaps are effective especially when you have a large number of pages (i.e., a news site!). Sitemaps update when new content is added and help Google find content based on a set of criteria (for example, if it is an image, a news story or a video).
There are four main types of sitemaps. All sitemaps have a limit of 50,000 URLs:
Normal XML sitemap: This holds links to all the different pages on your site. Yoast Plugin will automatically make this for you.
Video sitemap: Used to help Google understand video content on your site
News sitemap:Helps Google find stories that are approved for Google News
Image sitemap: Helps crawlers find all of the images hosted on your site.
The more complex and detailed your sitemaps, the more organized your content is and therefore the easier it is for crawlers to find. In theory, this means it is easier to rank.
Sitemaps are not necessary for web crawlers to scan your site – Google will do it regardless – but it does make the effort easier. And if your site is small or new, sitemaps can help speed up the indexing process so you’re not relying on a small handful of backlinks.

What to do: Create a sitemap through Yoast SEO Plugin, Google XML Sitemaps or with the help of your development team. You can then submit your sitemap to Google through Google Search Console (on the sidebar, under “Index,” click “Sitemaps”).
Once processed successfully, GSC will notify you of any changes to your sitemap that you may need to fix. It will also provide you information on how many URLs Google finds in your sitemap and how many actually ended up being in Google’s index.
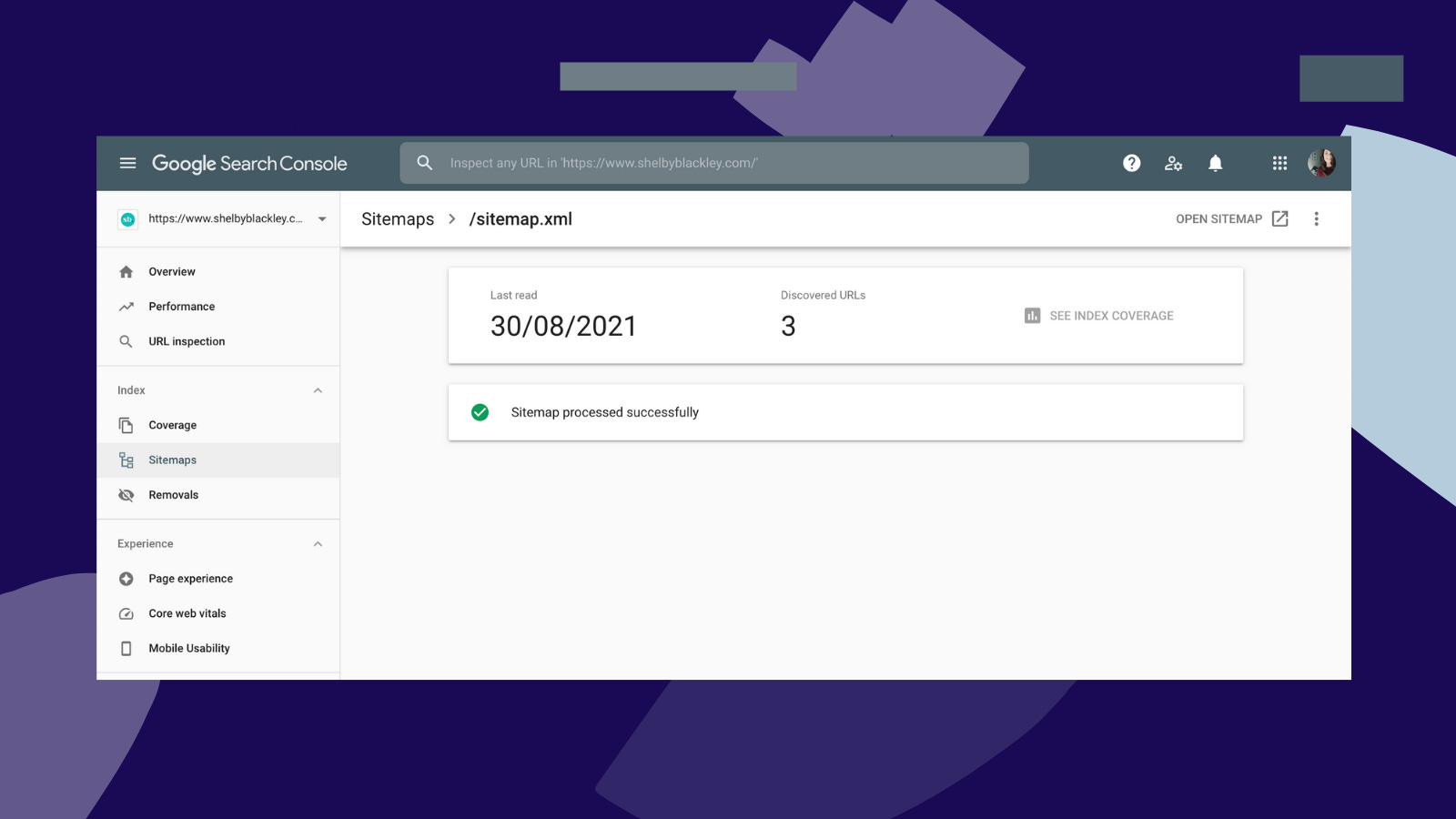
Break up your sitemaps based on what works for your site. If you are a major national news outlet, you’ll need multiple sitemaps that properly organize your content. But if you are a small independent local outlet, you may just need one main sitemap. Use your journalistic instincts.
HTTP Status Codes
What is it: HTTP status codes are the codes that explain what is happening on a page and whether the request has been completed successfully. They are issued by the computer server and tell the user what happened with the specific page they are on.
There are five classes of status codes that you need to know:
Informational responses (100-199): Information for the page is being processed but it is not complete yet.
Successful responses (200-299): Information for the page is processed and complete.
Redirects (300-399): The requested URL has changed, whether permanently or temporarily, and you are sent to a different URL.
Client errors (400-499): An issue on the site’s site. The page could not be processed.
Server errors (500-599): An issue on the server’s side. The page could not be processed.
The most common status codes you’ll use are:
200 (success);
301 (permanent redirect);
302 (temporary redirect);
404 (page not found);
500 (server error).
Knowing what these codes are, or what they mean, can help you make decisions about site structure and content.
What to do: Download the Chrome extension redirect path. It provides the exact path you take when you click on a URL and will explain to you the type of status code that renders with the page. This can help you immediately see when a page is returning a 301, a 404 or a 500 and can help diagnose problems, redirect URLs or ensure your site is not sending people in endless loops (like life).
Thin and Duplicate Content
What is it: Thin and duplicate content are two different types of content, but each have negative effects on your site.
Duplicate content is content that is provided more than once on the internet in the same or very similar way. This can become tricky for search engines as they do not know which version to include/exclude from their indices and don’t know which version to rank. This is why you may sometimes find the same wire on multiple different sites all ranking for the same keyword.
Duplicate content will impact your rankings. If a crawler finds the same story on four different sites, it will use its series of ranking factors (such as the URL, links to the story, headline, etc.) to decide which to actually provide users, while hiding the rest.
Thin content is content that Google deams to have little or no value. Content should not be posted for the sake of posting. Stories should add value, whether that is a personal opinion, originally reported advice or never-before-seen photos.
Longer pieces of content do tend to rank better, especially when it serves the intent. Anything less than 200 words is considered thin content.
What to do: Best practices are to avoid duplicate content, but sometimes that’s not possible. If you are a news organization that relies on wire services, you’ll naturally have the same story as other sites. That’s ok! We can try to make it as different as possible while serving what your readers need. Add in original reporting links, videos, graphics, etc. If the story is posted on your site then syndicated elsewhere, ask if it’s possible to put a canonical URL on the other site to ensure Google knows yours is the original.
Thin content shouldn’t exist unless absolutely necessary (location, contact pages). Optimize your content through on-page best practices, keyword research and value that only your organization can provide.
The bottom line: Technical SEO is complex, technical (hehe), but also a huge component of success for your site. Ensure you keep these tips in your back pocket when optimizing stories.
FUN + GAMES
SEO quiz
The 5 W’s and 1 H are very common for ranking content. Which of the six tend to have the most links to it?
“How” articles
“Who” articles
“Why” articles
“What” articles
“When” articles
“Where” articles
RECOMMENDED READING
Google is testing a fact check label on Top Stories
The new page experience update is rolling out now and will be done by the end of August 2021
Learnings from analyzing the title change update in 10 sites (tip: the shorter the better)
How to research keywords: a step-by-step guide
NEXT WEEK: We’re off next week! And will return September 13.
Have something you’d like us to discuss? Send us a note on Twitter (Jessie or Shelby) or to our email: seoforjournalism@gmail.com.
(Don’t forget to bookmark our glossary.)
FUN + GAMES
The answer: “Why” articles tend to have, on average, 5.66 sites linking to them. “How” follows shortly after, with just under five average sites linking to them.
Written by Jessie Willms and Shelby Blackley